Basic Web Scraping in Ruby with Mechanize
As I mentioned previously, as a side project, I created a site to collect average prices for World of Warcraft Trading Card Game cards. Here’s how I wrote the code in Ruby to gather the data I needed from various card store websites.
Mechanize
I use Mechanize to interact with the sites I need data from: to visit URLs, pull down the HTML, and even submit forms. Mechanize fills the role of a headless browser, though it doesn’t do javascript.
Here’s code to print out google’s home page:
require 'mechanize'
# Create mechanize instance
mechanize = Mechanize.new
# Get the page
page = mechanize.get('http://google.com')
puts page.body
The Mechanize::get call returns us a Mechanize::Page instance. We can use this to do some basic html parsing, and to find links and follow them, or to find forms and fill them out and submit them. But primarily, I use Nokogiri through the Page object, to search HTML using XPath.
Using XPath
XPath is a query language used to find nodes in XML, and therefore, HTML. (according to the docs, Nokogiri cleans up badly formed HTML as best it can, and my experience so far has been that it does just fine.)
The trickiest part is figuring out what XPath query to use. I use a Chrome extension called “XPath Helper” for this. You can click an element to get the corresponding XPath, and then play with the XPath query to see how to generalize it to pickup similar elements on that page.
Finding Card Categories
For example, say I wanted to get links to all the categories of cards on a page like this:
In Chrome, I’d hit ctrl-shift-X to turn on XPath Helper. Then I’d hold down shift, and roll over one of the category names (let’s try “Betrayal of the Guardian”), which would turn yellow. While still rolled over it, I release shift, and now I can edit the query to generalize it.
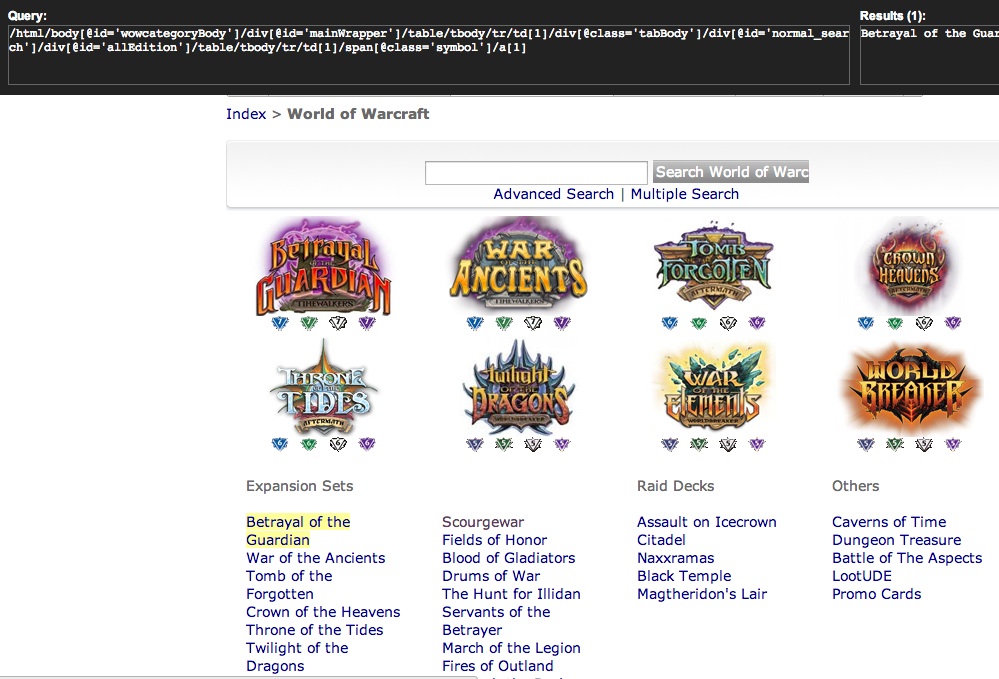
So the XPath query starts out like this:
/html/body[@id='wowcategoryBody']/div[@id='mainWrapper']/table/tbody/tr/td[1]/div[@class='tabBody']/div[@id='normal_search']/div[@id='allEdition']/table/tbody/tr/td[1]/span[@class='symbol']/a[1]
NOTE: As the XPath Helper extension mentions, the <tbody> tag inside tables isn’t really in the html coming down from the site; Chrome adds it artificially. So we need to make sure to remove the <tbody> from the query before you give it to Nokogiri, or the query won’t find anything in Ruby. Delete the <tbody> but leave the double // so the query matches both in XQuery Helper and in Nokogiri:
/html/body[@id='wowcategoryBody']/div[@id='mainWrapper']/table//tr/td[1]/div[@class='tabBody']/div[@id='normal_search']/div[@id='allEdition']/table//tr/td[1]/span[@class='symbol']/a[1]
Now we want to generalize this to find all categories, not just the one we chose. Those [1]’s are what’s selecting only the first column, or first anchor. So we can experiment in the query removing those, and watch as the yellow highlight updates in Chrome.
We end up with this query:
/html/body[@id='wowcategoryBody']/div[@id='mainWrapper']/table//tr/td[1]/div[@class='tabBody']/div[@id='normal_search']/div[@id='allEdition']/table//tr/td/span[@class='symbol']/a
Note in the screenshot that the XPath Helper “Results” listbox shows the names of all the categories that have been matched by the query.
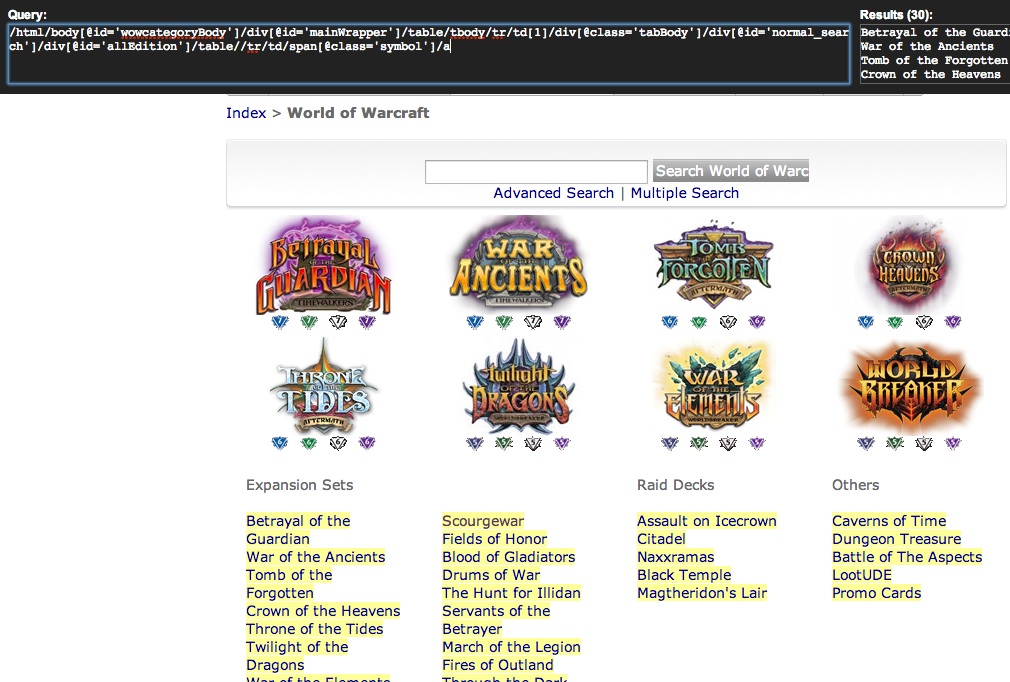
I prefer to simplify the query, to try to make it both cleaner and hopefully more resilient to future site changes. In XPath queries, a // will match anything, so we can delete the first part of the query and simplify it down to:
//div[@id='allEdition']/table//tr/td/span[@class='symbol']/a
This is a matter of keeping enough of the query to match only what we want, while removing anything that’s extraneous. Yes, this is subjective.
Now if we turn this into Ruby code to use Mechanize and Nokogiri to pick out the categories, it looks like this:
require 'mechanize'
require 'nokogiri'
# Create Mechanize instance
mechanize = Mechanize.new
# Retrieve the categories page
front_page = mechanize.get('http://www.mtgmintcard.com/wow_category.php')
# Find the category links
category_links = front_page.search "//div[@id='allEdition']/table//tr/td/span[@class='symbol']/a"
category_links.each do |cat_link|
# NOTE: actual link is in cat_link["href"]
puts cat_link.text
end
When run, the output will look something like this:
Betrayal of the Guardian
War of the Ancients
Tomb of the Forgotten
Crown of the Heavens
Throne of the Tides
Twilight of the Dragons
War of the Elements
Worldbreaker
Icecrown
Archives
... <snip> ...
Drilling down to find products
Let’s modify the loop to actually click through the link for each category, and retrieve the result:
category_links.each do |cat_link|
# Create a Page::Link and follow it.
result_page = Mechanize::Page::Link.new( cat_link, mechanize, front_page ).click
puts result_page.at('//title').text # Print the page title
end
The ugly line to create the link and click it is necessary because we aren’t using the Mechanize::Page’s ability to find links (see Mechanize::Page.links and Mechanize::Page::link_with), but are getting the link through Nokogiri instead. (I prefer to run everything through Nokogiri/XPath instead of using the Mechanize::Page method, but you don’t have to.)
Ok, let’s look at one of these product pages, and figure out how to get product data out of it:
http://www.mtgmintcard.com/world-of-warcraft/english-regular/betrayal-of-the-guardian
This page has a table with a bunch of rows, one product per row. Let’s figure out an XPath query to get all the rows in that table.
First, using XPath Helper, select let’s select the column with a product name in it. The query looks something like this:
/html/body[@id='wowsearchresultBody']/div[@id='mainWrapper']/table/tbody/tr/td[1]/div[@id='indexDefault']/table[@class='resultList']/tbody/tr[@class='darkRow'][1]/td[2]
The first thing I notice is that every other row has a class='darkRow', but we want ALL the rows, not just every one. Let’s clip off everything after the last tr. I’ll cut out the tbodys, too:
/html/body[@id='wowsearchresultBody']/div[@id='mainWrapper']/table//tr/td[1]/div[@id='indexDefault']/table[@class='resultList']//tr
That query picks up the top row that has column names as well, but that’s ok, we’ll worry about that later.
Looking at the query, we really want all the rows in the table with a class of resultList. So let’s simplify it to:
//table[@class='resultList']//tr
Again, you can verify this query works in XPath Helper.
Ok, let’s get paths to individual product names and prices. By experimenting, we can figure out that this selects all the names (which are in the second column, hence the [2]):
//td[2]/a[@class='opacityit']
This gets us all the prices:
//td[8]/span[@class='productListPrice']
If we’re not sure those will always be in the second and eighth columns, we could leave the [2] and [8] out of the queries.
Ok, now we’re to going to put it together, to iterate over all the rows in the table, and find the product name and price for each row, if there is one:
# Iterate over all the rows in the resultList table
result_page.search("//table[@class='resultList']//tr").each do |row|
# Name
name_node = row.at(".//td[2]/a[@class='opacityit']")
unless name_node
next
end
# Price
price_node = row.at(".//td[8]/span[@class='productListPrice']")
unless price_node
next
end
puts "%s: %s" % [name_node.text, price_node.text]
end
Note that . at the start of the at queries we’re doing on each row. If we left that off, the XPath query would actually go back to the top of the DOM, instead of only searching inside the row node.
Ok, so now we’re getting the name and price of cards on the first page in a category. We need to be able to click the “Next” link on each page to get all the results:
next_page_link = result_page.at "//a[text()='Next']"
if next_page_link
result_page = Mechanize::Page::Link.new( next_page_link, mechanize, result_page ).click
end
That query //a[text()='Next' means ‘find all the <a> tags where the text is “Next”’.
Alright, let’s put it all together. This will iterate over all the categories, drill down into each one, and pull out name and price data for all the products in that category:
require 'mechanize'
require 'nokogiri'
# Create Mechanize instance
mechanize = Mechanize.new
# Retrieve the categories page
front_page = mechanize.get('http://www.mtgmintcard.com/wow_category.php')
# Find the category links
category_links = front_page.search "//div[@id='allEdition']/table//tr/td/span[@class='symbol']/a"
category_links.each do |cat_link|
# Create a Page::Link and follow it.
result_page = Mechanize::Page::Link.new( cat_link, mechanize, front_page ).click
while result_page do
puts result_page.at('//title').text # Print the page title
# Iterate over all the rows in the resultList table
result_page.search("//table[@class='resultList']//tr").each do |row|
# Name
name_node = row.at(".//td[2]/a[@class='opacityit']")
unless name_node
next
end
# Price
price_node = row.at(".//td[8]/span[@class='productListPrice']")
unless price_node
next
end
puts "%s: %s" % [name_node.text, price_node.text]
end
next_page_link = result_page.at "//a[text()='Next']"
if next_page_link
result_page = Mechanize::Page::Link.new( next_page_link, mechanize, result_page ).click
else
result_page = nil
end
end
end
The output will look something like this:
Betrayal of the Guardian - World Of Warcraft TCG (Cryptozoic)
A Demonic Presence: $0.29
Aegwynn, Guardian of Tirisfal: $0.24
Ancient Moonkin Form: $0.24
Arcane Anomaly: $0.24
Arcane Protector: $0.24
Arcane Shock: $0.24
Archdruid Fandral Staghelm: $2.24
Assault on Blackrock Spire: $0.24
Atiesh, Greatstaff of the Guardian: $0.24
Bastion of Defense: $0.24
Belthira the Black Thorn: $8.49
Bianca, Timewalker Mage: $0.24
Bigbelly, Furbolg Chieftain: $0.24
Bitey: $0.24
Blackfang Tarantula: $0.29
... <snip> ...
That’s the basics of how I pull out product name and price information from different stores in my WoWTCG card pricelist site. I plan to make another post going up one level, and documenting what I do with this information once I have it.
Thanks!
Christopher Brooks 05 January 2014